製品・サービス
{kind=link}
単一実験によるモノクローナル抗体の詳細な特性解析
モノクローナル抗体は最も重要なタンパク質医薬品の1つです。抗体医薬開発で重要なステップとして、配列解析、変異解析、糖鎖解析およびその他の重要な翻訳後修飾の解析等、抗体分子の詳細な特性解析が挙げられます。これらの情報を得るためには、通常、複数の実験が必要とされます。
人による結果の統合・解釈は通常異なる実験結果を分析するために必要とされています。このプロセスは現在、時間がかかりエラーを生みやすいプロセスとなっています。これに対し、Rapid Novor社では、LC-MS/MSを利用して得られたデータの解析を自動化したワークフローを開発し、抗体の詳細な特性解析に利用しています。
手順
モノクローナル抗体は還元され、アルキル化された後、6種類の酵素(トリプシン、キモトリプシン、AspN、GluC、プロテナーゼKおよびペプシン)で消化されました。
各消化後のサンプルをLC-MS/MSで測定しました。ペプチドの de novo シークエンシングには独自のNovorソフトウェアが使用されました。
抗体配列データベースから参照配列を探索するためには独自データベースサービスサーチソフトFasterDBが使用されました。ペプチド de novo シークエンシングの結果は相対的な位置を決定するため、参照配列の上にマッピングされました。
de novo シークエンシングの結果得られた配列間で一致するコンセンサス配列は実際のタンパク質の部分配列であると判断されました。1次配列が決定された後、再度FasterDBを利用し、糖鎖修飾や他の翻訳後修飾を決定するためにMS/MSスペクトルが1次配列上にマッピングされました。
次いで各糖鎖修飾や他の翻訳後修飾のピーク面積が計算されました。ロイシンとイソロイシンは抗体データベース中の出現率やキモトリプシンおよびペプシンによる消化パターンの違いにより、明確に識別されました。
結果
上記ワークフローはWaters社のIgG-1標準抗体を用いて試験されました。重鎖および軽鎖の両方の全長配列がカバーされています(下図)。
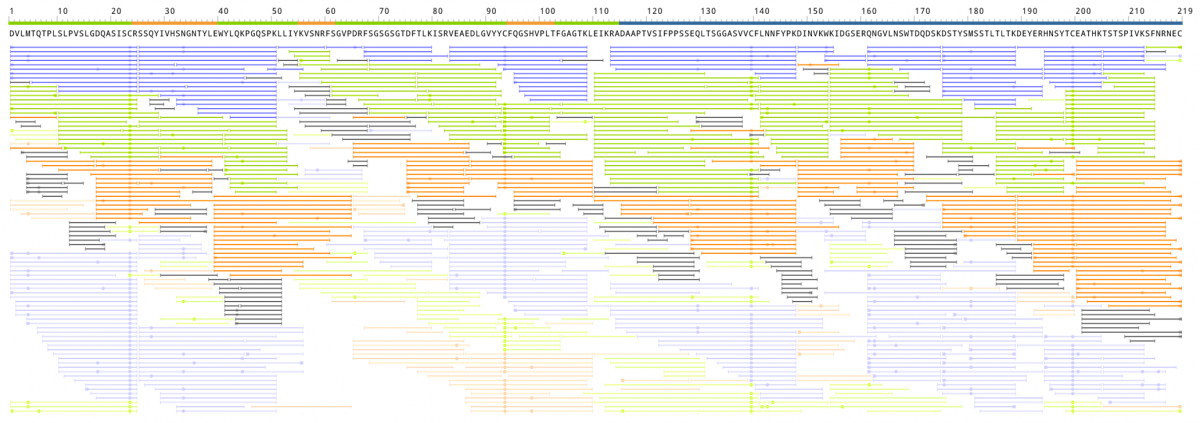
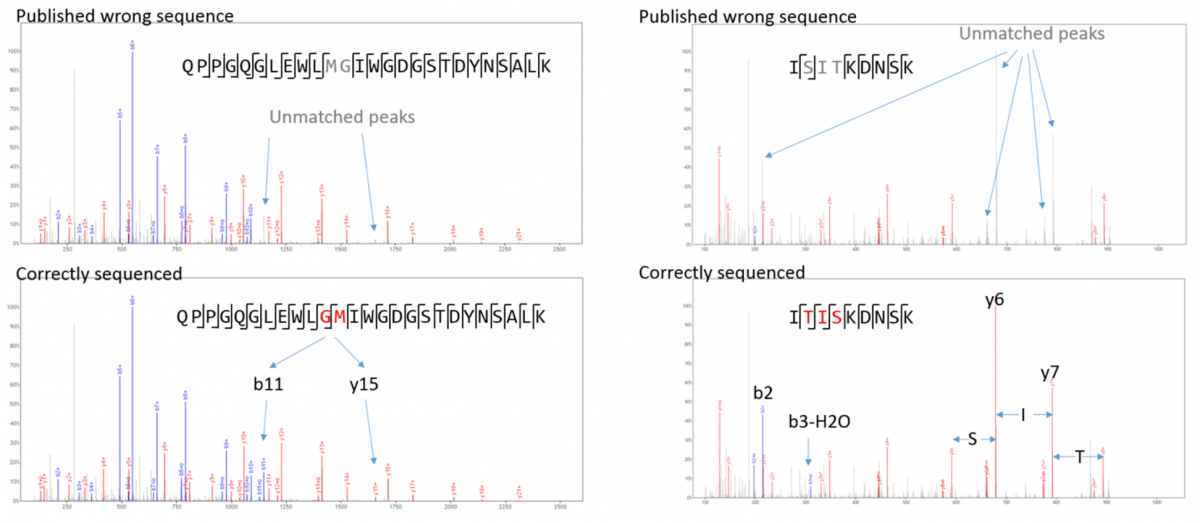
Waters社から提供されている配列情報と比較すると、重鎖に2か所の相違がみられました。最初の相違は49-50番目のアミノ酸残基で見られたMGとGMの2アミノ酸の相違であり、2か所目は68-70番目のアミノ酸残基で見られたSITとTISの相違でした。どちらの相違も可変部位に存在し、強いMS/MSシグナルピークによって裏付けされました。この変化によって全体の分子量は変化せず、若干MS/MSスペクトルが変化するだけであるため、 de novo ペプチドシークエンシングでのみ検出可能です。
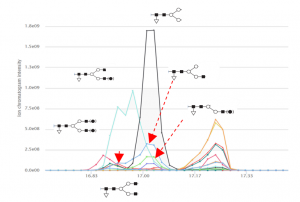
さらに、6種類の糖鎖修飾型が検出されました。6種類のうち5種類は異なる保持時間を示し、質量分析中のフラグメント化によるものではないことがわかります。
結論
このワークフローを用いることで、ルーティンで抗体の de novo シークエンシングと糖鎖修飾プロファイリングが可能になります。アミノ酸の推定は de novo シークエンシングの結果に基づいて行われます。これにより、ホモロジーに基づくシークエンシングによって検出されるより多くの変異を検出可能です。